Gemma: Understanding Google's New Open-Source LLM Family
Feb 23, 2024
•6 minute read•4394 views
The field of large language models (LLMs) is rapidly evolving, with new models pushing the boundaries of performance and capability. Google, a key player in this domain, has recently introduced Gemma, a family of open-source LLMs based on the research and technology behind their powerful Gemini models. This blog post dives into the technical details of Gemma, exploring its architecture, training data, and performance across various benchmarks.
Model Architecture: Building on the Transformer Decoder
| Parameters | 2B | 7B |
| d_model | 2048 | 3072 |
| Layers | 18 | 28 |
| Feedforward hidden dims | 32768 | 49152 |
| Num heads | 8 | 16 |
| Num KV heads | 1 | 16 |
| Head size | 256 | 256 |
| Vocab size | 256128 | 256128 |
Gemma's architecture is rooted in the Transformer decoder, a powerful neural network design that has revolutionized natural language processing. However, Gemma doesn't simply adopt the standard decoder; it incorporates several key improvements to enhance its capabilities:
Multi-Query Attention: This mechanism allows the model to attend to multiple parts of the input simultaneously, leading to better context understanding. Interestingly, Gemma adopts different attention variants depending on the model size. The 7 billion parameter model utilizes multi-head attention, where each head attends to different parts of the input. In contrast, the 2 billion parameter model employs multi-query attention, which uses a single key-value head but multiple query heads, proving more efficient for smaller models.
RoPE Embeddings: Instead of standard absolute positional embeddings, Gemma utilizes rotary positional embeddings (RoPE). These embeddings encode relative positions of tokens, allowing the model to better understand the relationships between words in a sentence. Additionally, RoPE embeddings are shared across input and output layers, reducing the overall model size.
GeGLU Activations: Gemma replaces the commonly used ReLU activation function with GeGLU (Gated Linear Unit). GeGLU has been shown to improve performance in Transformer models by allowing for more nuanced information flow through the network.
Normalizer Location: Deviating from the standard practice of normalizing either the input or output of each Transformer sub-layer, Gemma applies RMSNorm (Root Mean Square Layer Normalization) to both. This approach potentially leads to better gradient flow during training and improved model stability.
These architectural refinements, combined with the Transformer decoder foundation, equip Gemma with the ability to process and understand language effectively.
Pre-training: A Data Feast for Language Learning
Gemma models are pre-trained on a massive dataset of text and code, reaching up to 6 trillion tokens for the larger model. This data primarily consists of:
English Web Documents: This forms the bulk of the training data, exposing the model to a vast amount of natural language and diverse writing styles.
Mathematics Expressions: This data helps the model develop its reasoning and problem-solving capabilities, particularly in the domain of mathematics.
Code Snippets: By training on code, Gemma gains the ability to understand programming languages and potentially generate code itself.
It's crucial to note that the pre-training data undergoes rigorous filtering to minimize the risk of unwanted or unsafe outputs. This involves employing both rule-based and model-based techniques to remove harmful or low-quality content. Additionally, evaluation datasets are carefully separated from the training data to prevent data leakage and ensure accurate performance assessments.
Supervised Fine-Tuning: Tailoring Gemma for Specific Tasks
While pre-training equips Gemma with general language understanding capabilities, supervised fine-tuning (SFT) helps tailor the model for specific tasks. This involves training the model on a curated collection of prompt-response pairs, guiding it to learn the desired behavior.
The data used for SFT is meticulously selected based on side-by-side evaluations, where a larger, more capable model judges the quality of responses generated by different models on the same prompts. This process ensures that the data is aligned with human preferences and encourages the model to be helpful and informative.
Furthermore, similar to the filtering applied to the pre-training data, the SFT data is also cleansed to remove any potentially harmful or sensitive content. This multi-layered approach to data selection and filtering is crucial for ensuring that Gemma models are safe and responsible.
Reinforcement Learning from Human Feedback: Learning from Preferences
Gemma models are further fine-tuned using reinforcement learning from human feedback (RLHF). This technique allows the model to learn directly from human preferences, iteratively improving its responses.
In RLHF, human raters provide feedback on the model's outputs, and this feedback is used to train a reward function. The model then learns to optimize its responses to maximize this reward, effectively aligning its behavior with human preferences.
This approach is particularly useful for tasks where the desired output is subjective or nuanced, such as creative writing or dialogue generation. By incorporating human feedback directly into the training process, RLHF helps Gemma models become more engaging and human-like in their interactions.
Llama 2 Tokenizer: Similarities and Differences
One interesting observation is that Gemma's tokenizer shares many similarities with the Llama 2 tokenizer. Both are based on SentencePiece and operate at the byte-level, ensuring efficient handling of unknown tokens. However, there are some key differences:
Vocabulary Size: Gemma's vocabulary size is significantly larger, with 256k tokens compared to Llama 2's 32k. This allows Gemma to represent a wider range of words and concepts.
Special Tokens: Gemma utilizes a larger set of special tokens, including those for formatting dialogue and indicating roles in conversations. This enables the model to better handle conversational tasks and generate more coherent responses.
add_dummy_prefix: Unlike Llama 2, Gemma sets the add_dummy_prefix option to False. This indicates a subtle difference in how the models process input sequences.
These observations suggest that while Gemma's tokenizer builds upon the foundation laid by Llama 2, it incorporates specific modifications to enhance its capabilities and support its advanced functionalities.
Performance Evaluation: Surpassing Open-Source Alternatives
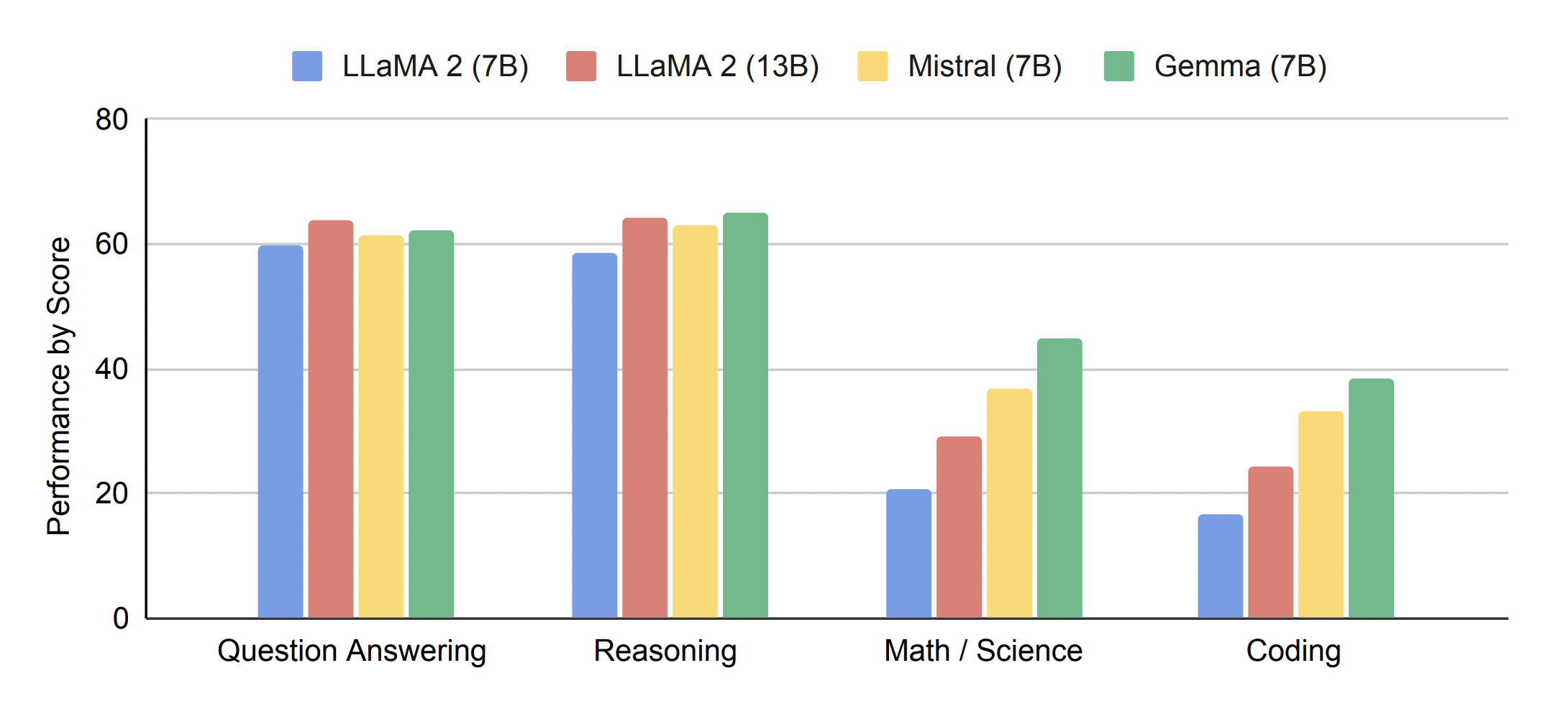
Gemma's performance is evaluated across a wide range of benchmarks, including question answering, commonsense reasoning, mathematics, coding, and more. The results are impressive, with Gemma models consistently outperforming other open-source LLMs of comparable size.
For instance, on the MMLU benchmark, which tests multi-task language understanding, Gemma 7B surpasses all other open-source models and even outperforms some larger models like LLaMA2 13B. Similarly, Gemma models excel in mathematics and coding tasks, significantly exceeding the performance of other open models on benchmarks like GSM8K and HumanEval.
These benchmark results clearly demonstrate that Gemma models are not only highly capable but also represent a significant advancement in the field of open-source LLMs.
Conclusion: A Powerful and Open LLM for the Community
Gemma's release marks a significant milestone in the LLM landscape. By providing open access to these powerful models, Google empowers researchers and developers to explore new applications and push the boundaries of AI innovation. With its state-of-the-art performance, comprehensive training data, and focus on safety, Gemma is poised to become a valuable tool for the AI community, fostering progress in various domains.
It's important to remember that, like any LLM, Gemma has limitations and requires further research to address challenges like factuality, alignment, and robustness. However, its open-source nature allows for collaborative efforts to overcome these hurdles and unlock the full potential of LLMs. As the field continues to evolve, Gemma stands as a testament to the power of open collaboration and serves as a stepping stone towards a future of increasingly sophisticated and beneficial language models.

Learn more about Rishiraj Acharya
Rishiraj is a triple Google Developer Expert (AI, Cloud & Kaggle). He is a Machine Learning Engineer at Intellitek, worked at Tensorlake, Dynopii & Celebal in the past and is a Hugging Face 🤗 Fellow. He is the organizer of TensorFlow User Group Kolkata and has been a Google Summer of Code contributor at TensorFlow. He is a Kaggle Competitions Master and has been a KaggleX BIPOC Grant Mentor. Rishiraj specializes in the domain of Natural Language Processing and Speech Technologies and works with AI for Medicine.